Portable executable explained throught rust code
Foreword: In this post I am going to discuss the PE format and write a parser to analyze the structure of this format. This is the first post about reverse engineering/malware analysis on my site. A tutorial on how to write a disassembler and debugger, again using rust, will be coming out soon. All of this will be preparatory to the series devoted to game hacking using rust that I plan to do.
Here you can find the repository of the project.
Let's start
Portable executable??
The Portable Executable (PE) format is a file format for executables, object code, DLLs and others used in 32/64 bit versions of Windows operating systems.
In short, it is a format that contains all the information required by the windows loader to run our file. For unix operating systems, there is a similar format called ELF.
Here an overview of the format:
 Credit : https://malware.news/t/portable-executable-file/32980
Credit : https://malware.news/t/portable-executable-file/32980
How can we parse PE using rust?
To parse the format we will use rust, and windows api, which contain the data structures we need to interpret the format correctly. There are several crates in rust, including the official microsoft bindings, which we are going to use. Microsoft, offers 2 different crates: windows and windows-sys, in a nutshell, the main difference is that the former offers methods on the bindings of the api that allow us to make the code more idiomatic, for example the Default trait on the structs offered by the windows api, this is at the expense of compilation time, which is faster in the latter case. In addition, it provides the most comprehensive API coverage for the Windows operating system, but you are not going to be able to use them in the no-std environment. More information here. In our case, we will use the windows crate.
As explained here, a classic method of deserializing a struct from a binary file is to read the file, go to the offset we are interested in and cast the struct containing our fields at that location, so that they are filled with the data we are interested in,of course correctly this is done if certain constraints are met,such as that the file is correctly formed.For simplicity's sake and in that this is not intended to be a "professional" pe parser, we will use this method, which of course has its disadvantages and advantages.
This is the code that deals with doing this in C , another similar approach would use memcpy.
C
struct my_struct { int a, b, c; char d[0xFF]; };
my_struct* s = (my_struct*) (pointer_to_file);
The correspondent in rust,we will use std::slice::from_raw_parts_mut, which is an unsafe function, we are using that because in the case that our file is badly formatted, we have no interest in continuing the program, alternatively there are other less performing options.
Rust
fn fill_struct_from_file<T>(structure: &mut T, file: &mut File) {
unsafe {
let buffer =
std::slice::from_raw_parts_mut(structure as *mut T as *mut u8, mem::size_of::<T>());
file.read_exact(buffer).expect("Unable to fill_struct_from_file");
}
}
I want to point it out that std::slice::from_raw_parts_mut takes as a parameter a data: *mut T , we are converting this pointer to a mutable pointer to u8 in order to call file.read_exact(buffer), which expect a buf: &mut [u8].
In short, we are creating a slice of the type &mut [u8] from our type T and then saving the content of the file in this struct.
Actually such kind of reasoning is very common in game hacking/malware writing, for example after a dll injection, we can go and read the memory of the process and fill our structs on which we will then implement the logic of what we want to do.
To be more precise, we also want the rust structure, to be the same as that of c/c++ in memory, to do this in rust there is a way to specify the alignment of our struct, which in our case will be #[repr(C)] , in the case of winapi in rust, it has already been specified.
Now, let's dive in the PE format!
The PE format
Before you go: a bit of terminology.
-
Base address, also known as image base. This is the preferred address of the first byte of the image when it is loaded into memory. This value is a multiple of 64K bytes. The default value for DLLs is 0X10000000. The default value for applications is 0X00400000, except in Windows CE where it is 0X00010000. Please note: This is a recommended value, in 2023 (the date of writing this post) in modern applications, address space layout randomization (aslr) is enabled for software security, so this value for most cases will be a random value generated on the fly.
-
Virtual address (VA) Allows reference to a part of the file in memory from the default base address.
-
Relative virtual address (RVA) Allows reference to a part of the file in memory without starting from the base address. This makes it more versatile , in that , to get the actual address you just have to add the base address to it.
-
Offset or Raw address It refers to the location of a value in the file saved on disk, thus without virtual memory.
In this post, I will explain the various structures from which the PE format is composed by placing side-by-side function calls that will dump them.
Note: I am not going to explain all field of the structures, but only those that will interest us for the parser, I will attach a link to the documentation for the other cases.
Rust
let mut pe = PE::new(file_path);
if !pe.is_valid() {
panic!("Invalid pe type")
}
pe.dump_dos_header();
pe.seek_magic();
pe.get_pe_type();
pe.seek_image_nt_header();
pe.dump_nt_header();
pe.dump_sections();
pe.dump_import();
pe.dump_export();
Dos header and Dos stub
We start with pe.dump_dos_header(); (we will talk about pe.is_valid() later).
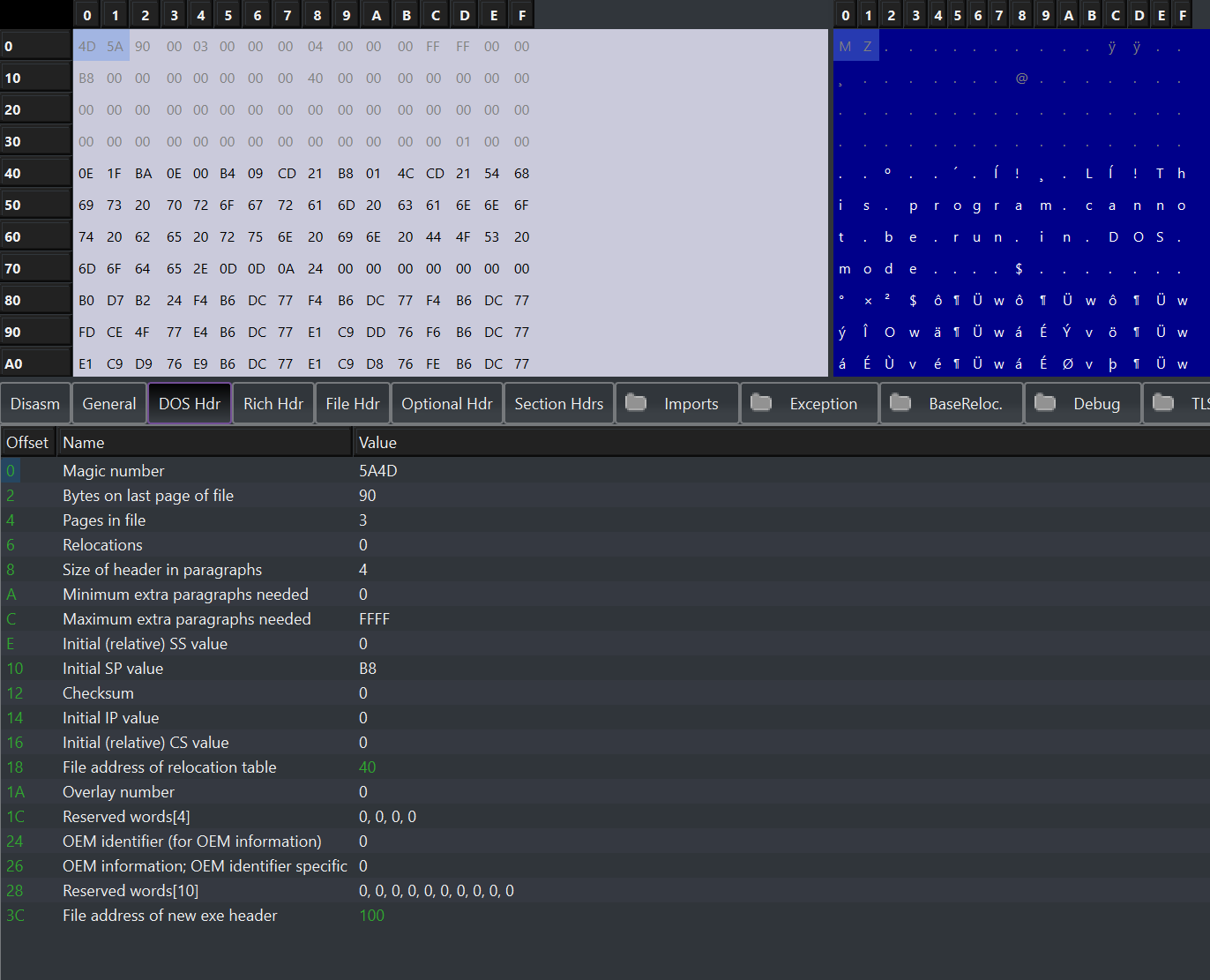
When we open an .exe file (or any file that follows pe format) at offset 0, we will find the so-called magic number, 5A4D("MZ") which is an acronym for Mark_Zbikowski.
C
typedef struct _IMAGE_DOS_HEADER { // DOS .EXE header
WORD e_magic; // Magic number
WORD e_cblp; // Bytes on last page of file
WORD e_cp; // Pages in file
WORD e_crlc; // Relocations
WORD e_cparhdr; // Size of header in paragraphs
WORD e_minalloc; // Minimum extra paragraphs needed
WORD e_maxalloc; // Maximum extra paragraphs needed
WORD e_ss; // Initial (relative) SS value
WORD e_sp; // Initial SP value
WORD e_csum; // Checksum
WORD e_ip; // Initial IP value
WORD e_cs; // Initial (relative) CS value
WORD e_lfarlc; // File address of relocation table
WORD e_ovno; // Overlay number
WORD e_res[4]; // Reserved words
WORD e_oemid; // OEM identifier (for e_oeminfo)
WORD e_oeminfo; // OEM information; e_oemid specific
WORD e_res2[10]; // Reserved words
LONG e_lfanew; // File address of new exe header
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
This is the initial structure of the file which is here for backward compatibility reasons and is called dos header, so we are not going to dig into this structure. After this, we have the dos stub which is needed in case you wanted to run the file in a dos system, the string:
This program cannot be run in DOS mode.
would be printed, in a nutshell, in the dos stub we find the code that prints this string (obviously if it is not a 16-bit dos program).
Now let's talk about code, I have defined this structure that will contain all the useful fields to parse the pe file, we will go into more detail on each of these as the post progresses.
Rust
struct PE {
pe_type: PEType,
file: File,
image_dos_header: IMAGE_DOS_HEADER,
image_nt_headers_32: IMAGE_NT_HEADERS32,
image_nt_headers_64: IMAGE_NT_HEADERS64,
sections: Vec<IMAGE_SECTION_HEADER>,
import_section: IMAGE_SECTION_HEADER,
export_section: IMAGE_SECTION_HEADER,
}
I promised you that we would talk about the function that checks whether the file we have follows the PE format. This is the function that takes care of that:
Rust
fn is_valid(&mut self) -> bool {
fill_struct_from_file(&mut self.image_dos_header, &mut self.file);
if self.image_dos_header.e_magic != IMAGE_DOS_SIGNATURE {
return false;
}
true
}
In a nutshell, we save the beginning of the file in a variable of type IMAGE_DOS_HEADER, so the fields of the struct will be filled with the corresponding values taken from the text file.
Next we just check that the first e_magic field matches the IMAGE_DOS_SIGNATURE ("MZ") constant.
After this check, we will go to print the dos header.
A very important field in this structure is the e_lfanew which will point to the location of the next header we are going to deal with: the file header.
File header
Before parsing it, we need to determine whether our file is 32-bit or 64-bit.
C
typedef struct _IMAGE_NT_HEADERS {
DWORD Signature; // The bytes are "PE\0\0".
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER32 OptionalHeader;
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
The pe file header, is defined in the struct _IMAGE_NT_HEADERS.
There is this version and the 64-bit version, the difference will be in the OptionalHeader field, which will be of type IMAGE_OPTIONAL_HEADER64.
The OptionalHeader, ironically is not that optional because the loader need it to run the executable
properly.
C
typedef struct _IMAGE_FILE_HEADER {
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
This is the image file header.
C
typedef struct _IMAGE_OPTIONAL_HEADER {
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
DWORD ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
This is the image optional header 32.
C
typedef struct _IMAGE_OPTIONAL_HEADER64 {
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
ULONGLONG ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
ULONGLONG SizeOfStackReserve;
ULONGLONG SizeOfStackCommit;
ULONGLONG SizeOfHeapReserve;
ULONGLONG SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER64, *PIMAGE_OPTIONAL_HEADER64;
This is the image optional header 64.
The magic field indicates what we want to find, which is whether the file is 32 or 64 bit.
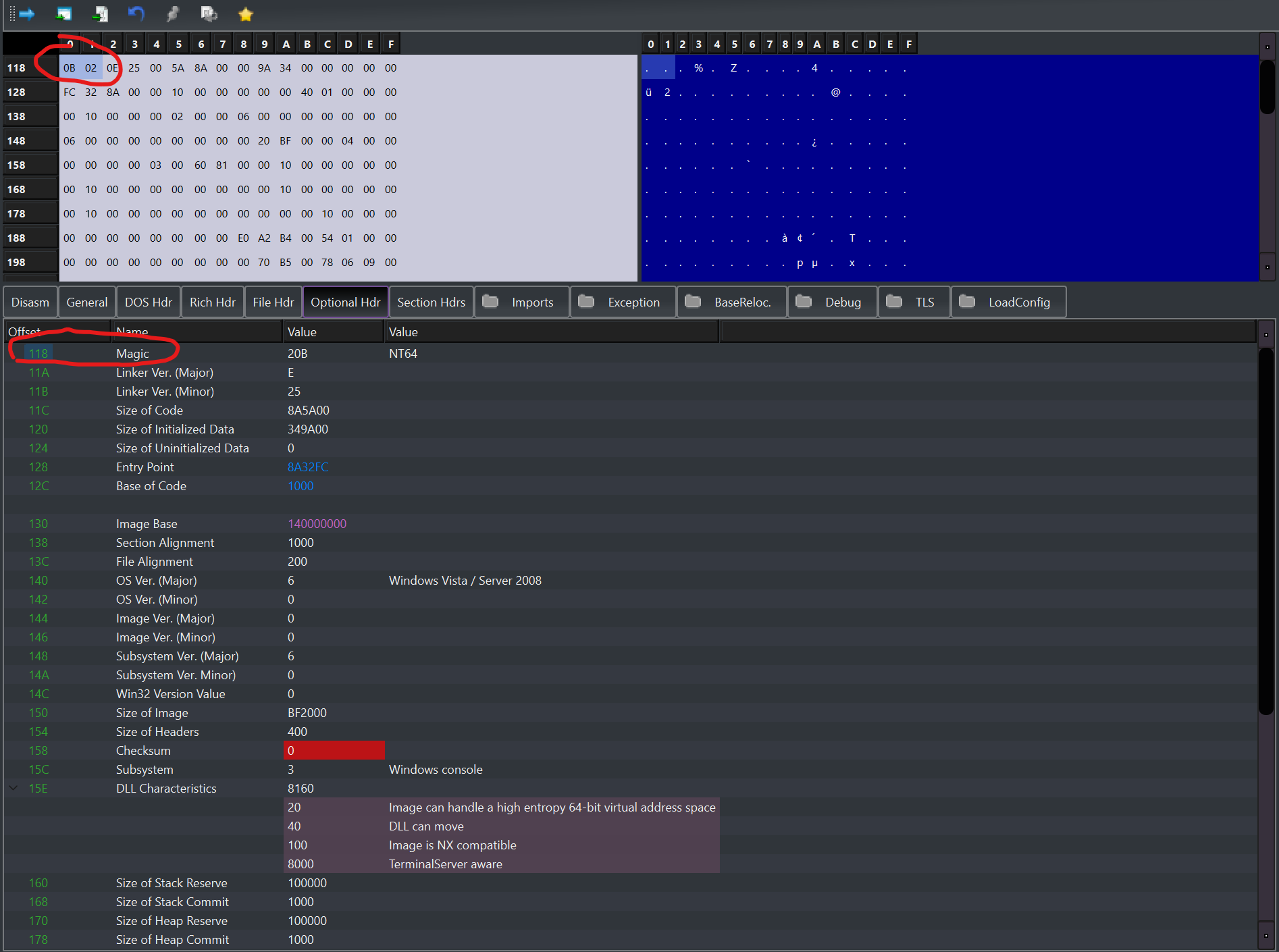
To access this field in the file we need to use some basic arithmetic, you should know that the e_lfanew field of the image dos header will point to the struct _IMAGE_NT_HEADERS, from this location we want to access the first element of the image optional header, so let's add the size of u32 (that would be the size of the dword signature in the image nt headers) and the size of the IMAGE_FILE_HEADER, in this way we will be at the beginning of the image optional header, being the first field what we are interested in (magic), we will just read a dword at that position to get it.
Rust
fn seek_magic(&mut self) {
let _magic_pos = self
.file
.seek(SeekFrom::Start(
self.image_dos_header.e_lfanew as u64
+ mem::size_of::<IMAGE_FILE_HEADER>() as u64
+ mem::size_of::<u32>() as u64, //size of pe signature
))
.expect("Unable to seek magic pe value in the file");
}
After reading this field, we can compare it with the constants IMAGE_NT_OPTIONAL_HDR32_MAGIC and IMAGE_NT_OPTIONAL_HDR64_MAGIC to figure out whether the file is 32-bit or 64-bit.
Rust
fn get_pe_type(&mut self) {
let mut pe_type = IMAGE_OPTIONAL_HEADER_MAGIC::default();
fill_struct_from_file(&mut pe_type, &mut self.file);
match pe_type {
IMAGE_NT_OPTIONAL_HDR32_MAGIC => {
self.pe_type = PEType::PE32;
}
IMAGE_NT_OPTIONAL_HDR64_MAGIC => {
self.pe_type = PEType::PE64;
}
_ => panic!("Invalid pe type"),
}
}
As I explained, there are 2 structures for the _IMAGE_NT_HEADERS, the 32 and the 64 structure, depending on the type of pe file we are going to parse the file and save the data in the appropriate structure, the offset of the structure, as already explained is in the e_lfanew field.
Rust
fn seek_image_nt_header(&mut self) {
let _image_nt_header_pos = self
.file
.seek(SeekFrom::Start(self.image_dos_header.e_lfanew as u64))
.expect("Unable to seek image_nt_header structure in the file");
}
Now all we have to do is dump the fields we are interested in.
I would like to pay special attention to the DataDirectory field in the optional image header, which is an array of IMAGE_DATA_DIRECTORY.
C
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
The VirtualAddress field is the RVA of the directory in question, while the Size is the size of the directory, in particular these fields will be useful for us to identify in which sections our directories are located.
To access the various directories these are the indexes.
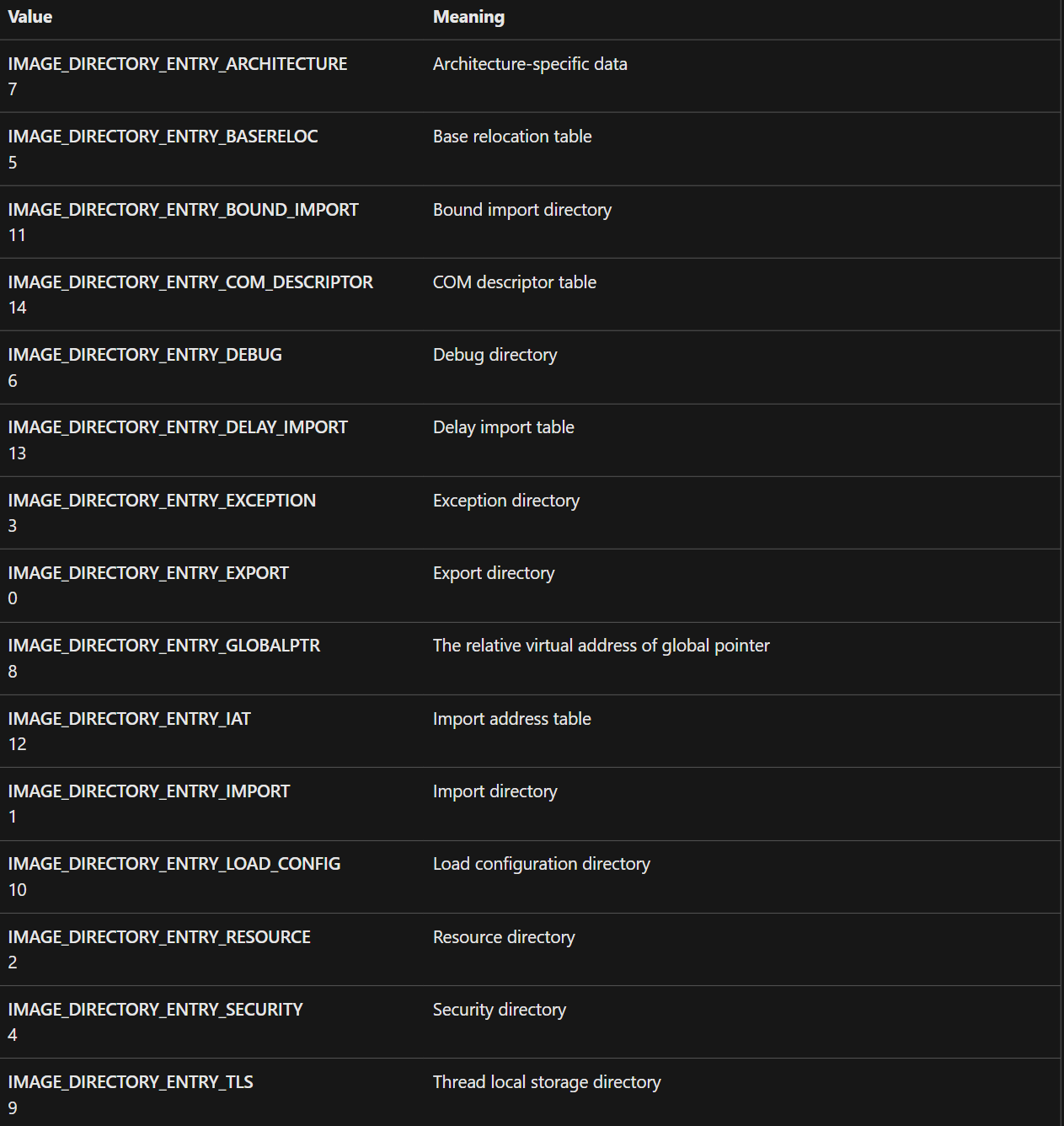
Now some may wonder, what is a data directory? In a nutshell it's a piece of data located within a section (which we will discuss later), this data is useful for the windows loader to properly execute the file, such as directory import and directory export.
Rust
fn dump_nt_header(&mut self) {
match self.pe_type {
PEType::PE32 => {
println!("Pe 32");
fill_struct_from_file(&mut self.image_nt_headers_32, &mut self.file);
println!("Image Nt Headers 32:");
//take a look at the source code if you are interested in seeing all the field printed
println!("Data directory:");
println!(" import directory:");
println!(
" Virtual address -> {:#x}",
self.image_nt_headers_32.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IMPORT.0 as usize]
.VirtualAddress,
);
println!(
" Size -> {:#x}",
self.image_nt_headers_32.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IMPORT.0 as usize]
.Size
);
println!(" export directory:");
println!(
" Virtual address -> {:#x}",
self.image_nt_headers_32.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_EXPORT.0 as usize]
.VirtualAddress,
);
println!(
" Size -> {:#x}",
self.image_nt_headers_32.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_EXPORT.0 as usize]
.Size
);
println!(" resource directory:");
println!(
" Virtual address -> {:#x}",
self.image_nt_headers_32.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_RESOURCE.0 as usize]
.VirtualAddress,
);
println!(
" Size -> {:#x}",
self.image_nt_headers_32.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_RESOURCE.0 as usize]
.Size
);
println!(" iat:");
println!(
" Virtual address -> {:#x}",
self.image_nt_headers_32.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IAT.0 as usize]
.VirtualAddress,
);
println!(
" Size -> {:#x}\n",
self.image_nt_headers_32.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IAT.0 as usize]
.Size
);
}
PEType::PE64 => {
println!("Pe 64");
fill_struct_from_file(&mut self.image_nt_headers_64, &mut self.file);
println!("Image Nt Headers 64:");
//take a look at the source code if you are interested in seeing all the field printed
println!("Data directory:");
println!(" import directory:");
println!(
" Virtual address -> {:#x}",
self.image_nt_headers_64.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IMPORT.0 as usize]
.VirtualAddress,
);
println!(
" Size -> {:#x}",
self.image_nt_headers_64.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IMPORT.0 as usize]
.Size
);
println!(" export directory:");
println!(
" Virtual address -> {:#x}",
self.image_nt_headers_64.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_EXPORT.0 as usize]
.VirtualAddress,
);
println!(
" Size -> {:#x}",
self.image_nt_headers_64.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_EXPORT.0 as usize]
.Size
);
println!(" resource directory:");
println!(
" Virtual address -> {:#x}",
self.image_nt_headers_64.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_RESOURCE.0 as usize]
.VirtualAddress,
);
println!(
" Size -> {:#x}",
self.image_nt_headers_64.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_RESOURCE.0 as usize]
.Size
);
println!(" iat:");
println!(
" Virtual address -> {:#x}",
self.image_nt_headers_64.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IAT.0 as usize]
.VirtualAddress,
);
println!(
" Size -> {:#x}\n",
self.image_nt_headers_64.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IAT.0 as usize]
.Size
);
}
}
}

Now that we have parsed the OptionalHeader(contained in the _IMAGE_NT_HEADERS), we can talk about sections.
Sections
A section contain the main content of the file, including code, data, resources, and other executable information. An example of a section, is .text, in which we usually find the (compiled) code we wrote.

To parse the sections correctly, first we need to know how many there are. To know this, in the header file, we have a field called, NumberOfSections which is obviously what we need.
What we are going to parse is defined in the _IMAGE_SECTION_HEADER.
C
typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME];
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
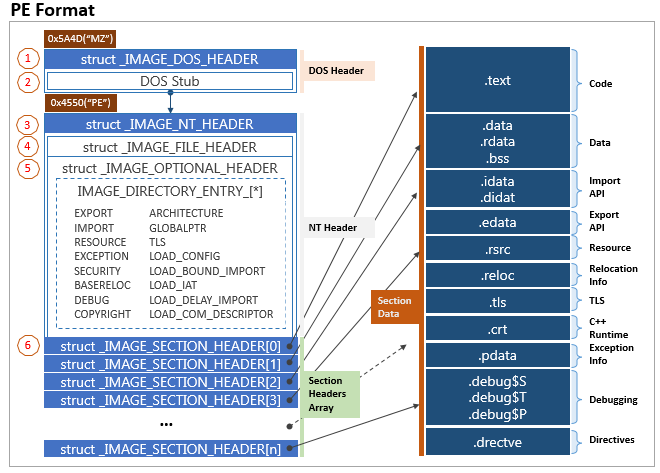 credit: https://tech-zealots.com/malware-analysis/pe-portable-executable-structure-malware-analysis-part-2/
credit: https://tech-zealots.com/malware-analysis/pe-portable-executable-structure-malware-analysis-part-2/
These sections, are in a table, which starts after the nt header position. So to access the nth table, we just multiply the size of the structure by the position we want to access.
Rust
fn seek_nth_section(&mut self, nth: usize) {
let image_nt_header_size = match self.pe_type {
PEType::PE32 => mem::size_of::<IMAGE_NT_HEADERS32>(),
PEType::PE64 => mem::size_of::<IMAGE_NT_HEADERS64>(),
} as u64;
let _nth_section_pos = self
.file
.seek(SeekFrom::Start(
self.image_dos_header.e_lfanew as u64
+ image_nt_header_size
+ (nth * mem::size_of::<IMAGE_SECTION_HEADER>()) as u64,
))
.expect("Unable to seek nth section in the file");
}
fn get_sections(&mut self) {
for i in 0..number_of_sections as usize {
self.seek_nth_section(i);
let mut section = IMAGE_SECTION_HEADER::default();
fill_struct_from_file(&mut section, &mut self.file);
self.sections.push(section);
}
}
Here is the code for dumping section's information.
Rust
fn dump_sections(&mut self) {
self.get_sections();
println!("Sections header:");
for section in &self.sections {
let section_name = std::str::from_utf8(§ion.Name).expect("Unable to get section name");
println!(" {}", section_name);
println!(" virtual address -> {:#x}", section.VirtualAddress);
unsafe {
println!(" virtual size -> {:#x}", section.Misc.VirtualSize);
}
println!(
" pointer to raw data -> {:#x}",
section.PointerToRawData
);
println!(" size of raw data -> {:#x}", section.SizeOfRawData);
println!(
" characteristics -> {:#x}\n",
section.Characteristics.0
);
}
}
Now comes the most difficult and most important part of the parser. We are going to parse the import directory and the export directory.
Import and Export directory
The import directory contains all the dlls (dynamic link libraries, you can see them as dynamic dependencies) and the functions within them that the program needs to run properly. The windows loader will fetch all the required dlls and map them to process memory so that our program can access them. Note: the import directory is very important, especially in reverse engineering and malware analysis, as it gives us a general idea of what the program will do (more info in future posts).
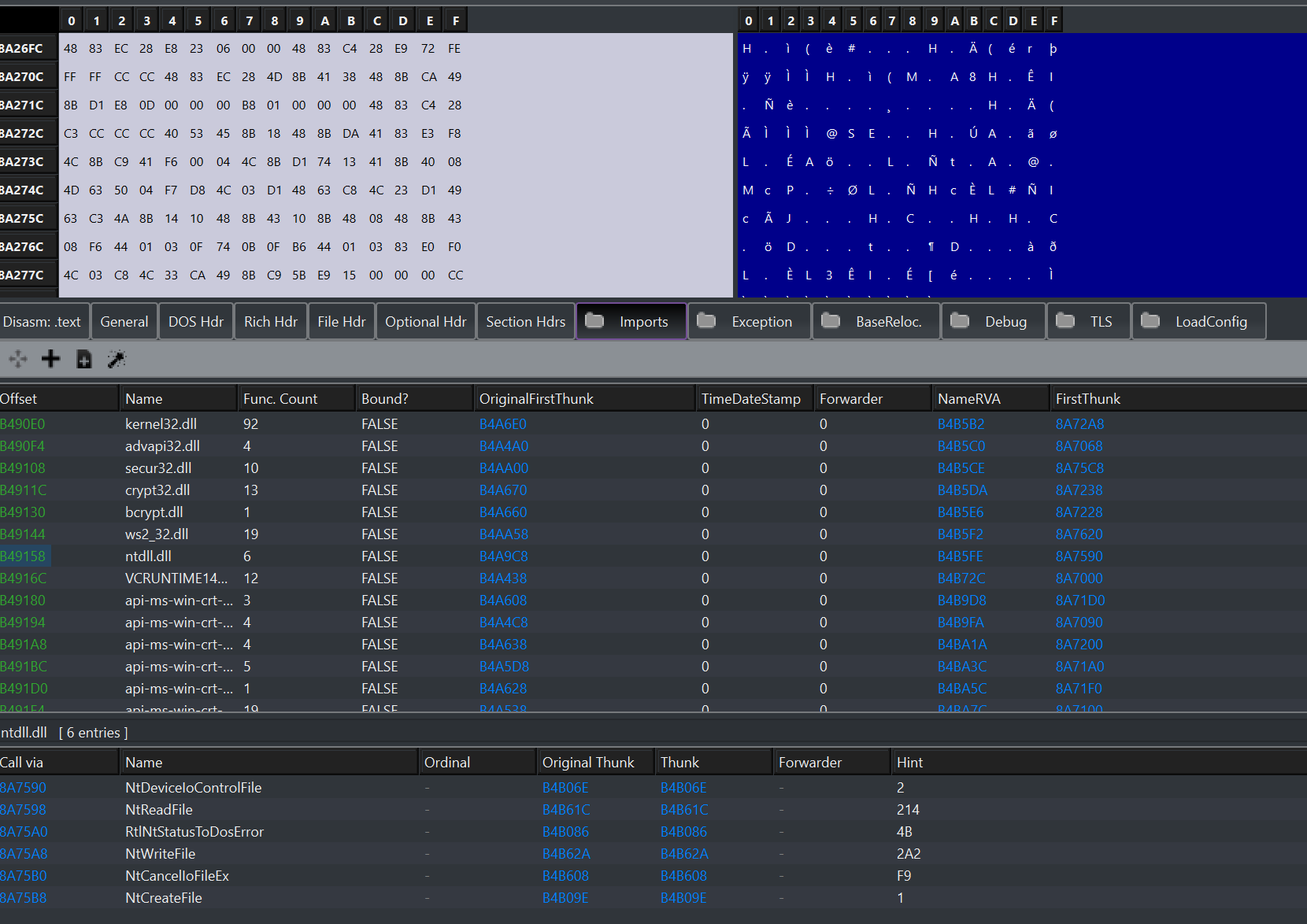
Before we delve into these two directories, I would like to remind you that as I have explained, these are located within a section, I will now explain how to find which section they are in, as to get the offset of these two in the binary will be necessary.
Now I can post the complete code to get the sections.
Rust
fn get_sections(&mut self) {
let (import_rva, export_rva, number_of_sections) = match self.pe_type {
PEType::PE32 => (
self.image_nt_headers_32.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IMPORT.0 as usize]
.VirtualAddress,
self.image_nt_headers_32.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_EXPORT.0 as usize]
.VirtualAddress,
self.image_nt_headers_32.FileHeader.NumberOfSections,
),
PEType::PE64 => (
self.image_nt_headers_64.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IMPORT.0 as usize]
.VirtualAddress,
self.image_nt_headers_64.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_EXPORT.0 as usize]
.VirtualAddress,
self.image_nt_headers_64.FileHeader.NumberOfSections,
),
};
for i in 0..number_of_sections as usize {
self.seek_nth_section(i);
let mut section = IMAGE_SECTION_HEADER::default();
fill_struct_from_file(&mut section, &mut self.file);
//we want to check in which section the import directory is
if import_rva >= section.VirtualAddress
&& import_rva < section.VirtualAddress + unsafe { section.Misc.VirtualSize }
{
self.import_section = section;
}
//we want to check in which section the export directory is
if export_rva >= section.VirtualAddress
&& export_rva < section.VirtualAddress + unsafe { section.Misc.VirtualSize }
{
self.export_section = section;
}
self.sections.push(section);
}
}
What we most care about is this piece of code:
Rust
fn get_sections(&mut self) {
let (import_rva, export_rva, number_of_sections) = match self.pe_type {
PEType::PE32 => (
self.image_nt_headers_32.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IMPORT.0 as usize]
.VirtualAddress,
self.image_nt_headers_32.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_EXPORT.0 as usize]
.VirtualAddress,
self.image_nt_headers_32.FileHeader.NumberOfSections,
),
PEType::PE64 => (
self.image_nt_headers_64.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IMPORT.0 as usize]
.VirtualAddress,
self.image_nt_headers_64.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_EXPORT.0 as usize]
.VirtualAddress,
self.image_nt_headers_64.FileHeader.NumberOfSections,
),
};
//we want to check in which section the import directory is
if import_rva >= section.VirtualAddress
&& import_rva < section.VirtualAddress + unsafe { section.Misc.VirtualSize }
{
self.import_section = section;
}
//we want to check in which section the export directory is
if export_rva >= section.VirtualAddress
&& export_rva < section.VirtualAddress + unsafe { section.Misc.VirtualSize }
{
self.export_section = section;
}
}
In a nutshell, what this code is doing is checking that the import/export rva is within the section range, so it can figure out which section it is in.
Basically is checking if section_address <= import_rva < last_section_address.
The code is fairly intuitive,
section.VirtualAddress + unsafe { section.Misc.VirtualSize } gives us the final address of the section , so we can check if the directory is within the latter.
Now comes the hard part... get ready.
Import directory
We know the rva of the import directory and the rva of the section we are in.
To get the offset of the directory import, we need the field, PointerToRawData, which we find in the struct that contains the section of the directory import.
This field, tells us where this section is located in the file on disk(the offset, in a nutshell), now all we have to do is make the difference between the rva of the import directory and the rva of the section we are in, note, the former will be greater than the latter, this way we get the distance from the import directory and the rva of the section.
Adding this distance to the offset of the a section, we get the actual position on disk of the import directory.
This logic will be repeated several times, so try to understand it thoroughly. This is also well explained here.
Now, the import information is contained in the IMAGE_IMPORT_DESCRIPTOR struct.
C
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics; /* 0 for terminating null import descriptor */
DWORD OriginalFirstThunk; /* RVA to original unbound IAT */
} DUMMYUNIONNAME;
DWORD TimeDateStamp; /* 0 if not bound,
* -1 if bound, and real date\time stamp
* in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT
* (new BIND)
* otherwise date/time stamp of DLL bound to
* (Old BIND)
*/
DWORD ForwarderChain; /* -1 if no forwarders */
DWORD Name;
/* RVA to IAT (if bound this IAT has actual addresses) */
DWORD FirstThunk;
} IMAGE_IMPORT_DESCRIPTOR,*PIMAGE_IMPORT_DESCRIPTOR;
We will have a number of these structs equal to the number of dlls imported, and each one will be after the other.
The fields we are interested in in this struct, are the Name, the OriginalFirstThunk and the FirstThunk.
Regarding the Name, it will contain an address that corresponds to the location of the file that contains the name of the dll, if the name address is zero, it means that we have finished all the imports.
What we will do, then, is to keep iterating and advancing (we will advance by the size of the IMAGE_IMPORT_DESCRIPTOR) until the imports are finished.
Regarding the FirstThunk and the OriginalFirstThunk the former, will point to the so-called IAT (import address table), and the latter to the ILT (import lookup table), also known as the import name table.
C
typedef struct _IMAGE_THUNK_DATA64 {
union {
ULONGLONG ForwarderString; // PBYTE
ULONGLONG Function; // PDWORD
ULONGLONG Ordinal;
ULONGLONG AddressOfData; // PIMAGE_IMPORT_BY_NAME
} u1;
} IMAGE_THUNK_DATA64;
typedef IMAGE_THUNK_DATA64 * PIMAGE_THUNK_DATA64;
typedef struct _IMAGE_THUNK_DATA32 {
union {
DWORD ForwarderString; // PBYTE
DWORD Function; // PDWORD
DWORD Ordinal;
DWORD AddressOfData; // PIMAGE_IMPORT_BY_NAME
} u1;
} IMAGE_THUNK_DATA32;
typedef IMAGE_THUNK_DATA32 * PIMAGE_THUNK_DATA32;
The structure they point to is _IMAGE_THUNK_DATA, on disk, the address of Function field will be the same as AddressOfData, at runtime however the address of Function, which corresponds to the IAT , will be overwritten by the loader with the function va.
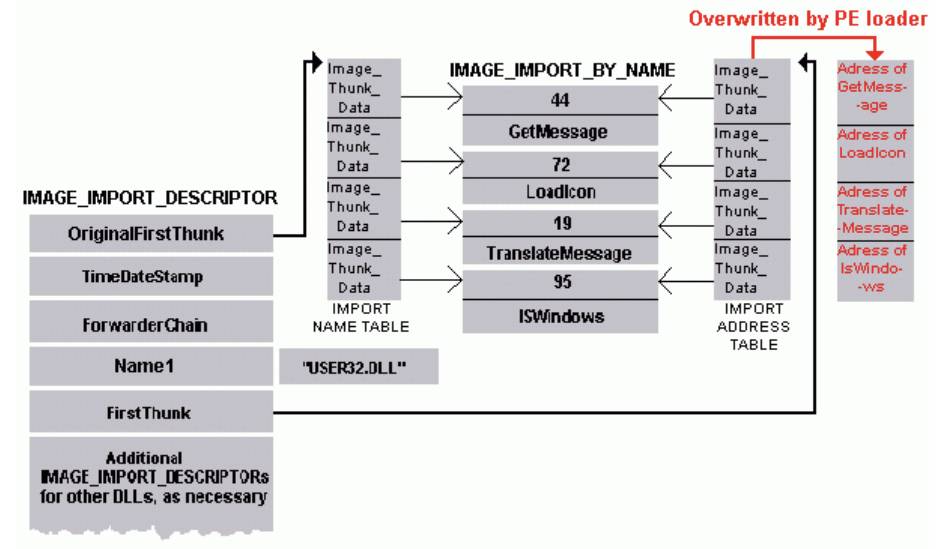
Note: this information is very useful for iat hooking :)
Now... some code.
Rust
fn dump_import(&mut self) {
let import_rva = match self.pe_type {
PEType::PE32 => {
self.image_nt_headers_32.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IMPORT.0 as usize]
.VirtualAddress
}
PEType::PE64 => {
self.image_nt_headers_64.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_IMPORT.0 as usize]
.VirtualAddress
}
};
let image_import_descriptor_offset = self.import_section.PointerToRawData
+ (import_rva - self.import_section.VirtualAddress);
let mut import_directory_nth = 0;
loop {
self.seek_nth_import(image_import_descriptor_offset, import_directory_nth);
let mut import_descriptor = IMAGE_IMPORT_DESCRIPTOR::default();
fill_struct_from_file(&mut import_descriptor, &mut self.file);
if import_descriptor.Name == 0 && import_descriptor.FirstThunk == 0 {
break;
}
let import_name_raw = self.import_section.PointerToRawData
+ (import_descriptor.Name - self.import_section.VirtualAddress);
let import_name = self.get_import_name(import_name_raw);
println!("import -> {}", import_name);
self.dump_thunk(import_descriptor);
import_directory_nth += 1;
}
}
It is missing to explain how to print the name and the various functions, precisely this part of the code.
Rust
let import_name_raw = self.import_section.PointerToRawData
+ (import_descriptor.Name - self.import_section.VirtualAddress);
let import_name = self.get_import_name(import_name_raw);
println!("import -> {}", import_name)
self.dump_ilt(import_descriptor);
To get the location of the file where the string is, we must perform the reasoning done earlier, so add to the offset of the section the address pointing to the name minus the virtual address of the section.
Now a question remains, especially in rust:
How can I read a cstring in a file at a given location?
Once we have the address, we will go and create a BufReader and set the location to the address offset. This way we can use the read_until method, which will continue reading the file until it finds the null character, saving it in a Vec<u8>.
Next we convert the Vec to a String.
Rust
fn get_import_name(&mut self, import_name_raw: u32) -> String {
let mut buf_reader = self.seek_import_name(import_name_raw);
read_cstring_from_file(buf_reader)
}
fn seek_import_name(&mut self, import_name_raw: u32) -> BufReader<&File> {
let mut buf_reader = BufReader::new(&self.file);
buf_reader
.seek(SeekFrom::Start(import_name_raw as u64))
.expect("Unable to seek import name");
buf_reader
}
fn read_cstring_from_file(mut buf_reader: BufReader<&File>) -> String {
let mut import_name = vec![];
buf_reader
.read_until(b'\0', &mut import_name)
.expect("Unable to read file until null character");
CStr::from_bytes_until_nul(&import_name)
.expect("Unable to convert bytes to cstr")
.to_string_lossy()
.to_string()
}
Now we are going to dump the name of the functions and related ILT and IAT.
The struct _IMAGE_THUNK_DATA will contain this info, since there can be multiple functions in a dll, to know when they are finished we need to check that all the fiels in the struct are set to zero.
To advance from thunk to thunk, we obviously just need the position of the first one and then multiply the size of the struct with the index we want, just as if it were accessing an element of an array.
There are two ways to call a function either by name, or by ordinal.
The ordinal represents the position of the function's address pointer in the export directory.
To check that the function is imported by ordinal, just check that the most significant bit of AddressOfData is set, if it, all we need to do is print the ordinal.
In case it is imported by name instead, we need to read the address in AddressOfData, which will point to this structure.
C
typedef struct _IMAGE_IMPORT_BY_NAME {
WORD Hint;
CHAR Name[1];
} IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME;
Then we need to add 2 to the memory pointer by this address to skip the Hint field and get the string.
After that we just have to read the cstring at that location and print the address in ILT and IAT.
Rust
fn dump_thunk(&mut self, import_descriptor: IMAGE_IMPORT_DESCRIPTOR) {
match self.pe_type {
PEType::PE32 => {
let mut f_counter = 0;
loop {
let ilt_raw = self.import_section.PointerToRawData
+ (unsafe { import_descriptor.Anonymous.OriginalFirstThunk }
- self.import_section.VirtualAddress)
+ (f_counter * mem::size_of::<IMAGE_THUNK_DATA32>() as u32);
self.seek_thunk(ilt_raw);
let mut thunk_data = IMAGE_THUNK_DATA32::default();
fill_struct_from_file(&mut thunk_data, &mut self.file);
if unsafe {
thunk_data.u1.AddressOfData == 0
&& thunk_data.u1.ForwarderString == 0
&& thunk_data.u1.Function == 0
&& thunk_data.u1.Ordinal == 0
} {
break;
}
if unsafe { thunk_data.u1.AddressOfData } & (1 as u32) << 31 == 1 {
println!("Ordinal -> {}", unsafe { thunk_data.u1.Ordinal });
} else {
let f_import_name_raw = self.import_section.PointerToRawData
+ (unsafe { thunk_data.u1.AddressOfData }
- self.import_section.VirtualAddress)
+ 2;
let name = self.get_f_name(f_import_name_raw);
println!("name -> {}", name);
println!(" iat function address -> {:#x}", unsafe {
thunk_data.u1.Function
});
println!(" function address -> {:#x}", unsafe {
thunk_data.u1.AddressOfData
});
}
f_counter += 1;
}
}
PEType::PE64 => {
let mut f_counter = 0;
loop {
let ilt_raw = self.import_section.PointerToRawData
+ (unsafe { import_descriptor.Anonymous.OriginalFirstThunk }
- self.import_section.VirtualAddress)
+ (f_counter * mem::size_of::<IMAGE_THUNK_DATA64>() as u32);
self.seek_thunk(ilt_raw);
let mut ilt_data = IMAGE_THUNK_DATA64::default();
fill_struct_from_file(&mut ilt_data, &mut self.file);
if unsafe {
ilt_data.u1.AddressOfData == 0
&& ilt_data.u1.ForwarderString == 0
&& ilt_data.u1.Function == 0
&& ilt_data.u1.Ordinal == 0
} {
break;
}
if unsafe { ilt_data.u1.AddressOfData } & (1 as u64) << 63 == 1 {
println!("Ordinal -> {}", unsafe { ilt_data.u1.Ordinal });
} else {
let f_import_name_raw = self.import_section.PointerToRawData
+ (unsafe { ilt_data.u1.AddressOfData } as u32
- self.import_section.VirtualAddress)
+ 2;
let name = self.get_f_name(f_import_name_raw);
println!("name -> {}", name);
println!(" function address in IAT -> {:#x}", unsafe {
thunk_data.u1.Function
});
println!(" function address in ILT -> {:#x}", unsafe {
thunk_data.u1.AddressOfData
});
}
f_counter += 1;
}
}
}
}
fn get_f_name(&mut self, f_import_name_raw: u32) -> String {
let buf_reader = self.seek_f_name(f_import_name_raw);
read_cstring_from_file(buf_reader)
}
fn seek_f_name(&mut self, f_import_name_raw: u32) -> BufReader<&File> {
let mut buf_reader = BufReader::new(&self.file);
buf_reader
.seek(SeekFrom::Start(f_import_name_raw as u64))
.expect("Unable to seek name");
buf_reader
}
fn seek_thunk(&mut self, ilt_raw: u32) {
self.file
.seek(SeekFrom::Start(ilt_raw as u64))
.expect("Unable to seek import name");
}
Now we are going to dump the export directory.
Export directory
Regarding the export directory, we will find it(in most cases) in the dlls, what we are interested in is that this directory contains the name and the corresponding function that can be called by a program that will have that dll as a dependency.
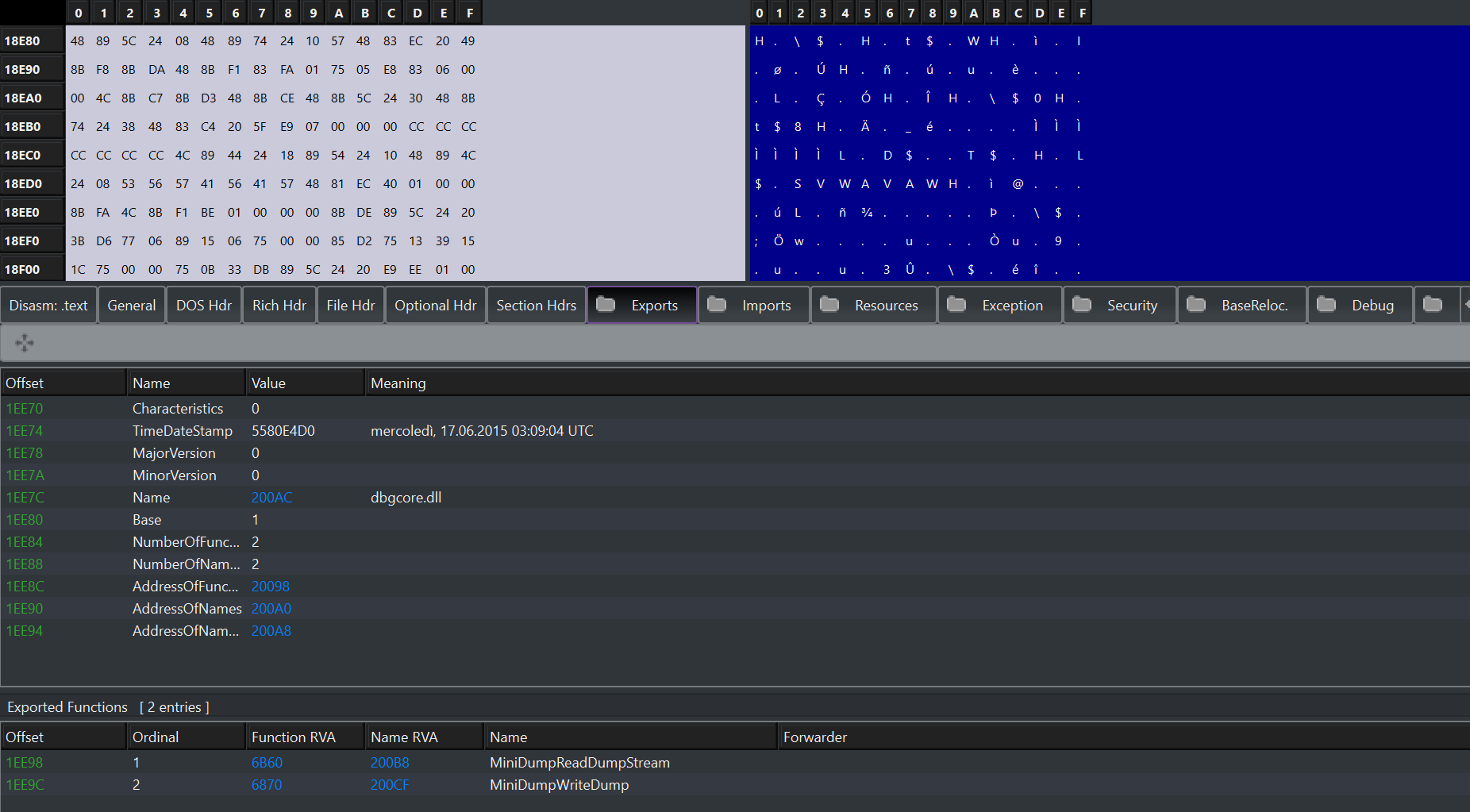
The export directory is defined in this way.
C
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name; // RVA to the ASCII string with the name of the DLL
DWORD Base; // starting value for the ordinal number of the exports.
DWORD NumberOfFunctions; // number of entries for exported functions.
DWORD NumberOfNames; // number of string names for the exported functions.
/*
* These three values correspond to three RVAs
* for tables, each table save some data:
* AddressOfFunctions: each table entry saves the RVA of an exported function.
* AddressOfNames: each table entry saves the RVA to a name of function.
* AddressOfNamOrdinals: each table entry saves 16-bit ordinals indexes of functions.
*
* We can use these three tables to get the address of a DLL function
* by name, using the next operation:
* i = Search_ExportNamePointerTable (ExportName);
* ordinal = ExportOrdinalTable [i];
* SymbolRVA = ExportAddressTable [ordinal - Base];
*/
DWORD AddressOfFunctions;
DWORD AddressOfNames;
DWORD AddressOfNameOrdinals;
} IMAGE_EXPORT_DIRECTORY,*PIMAGE_EXPORT_DIRECTORY;
First we should note that the export directory may not be present; if it is not present, the rva of the export directory will be zero, otherwise, as we did for the import, we want to get the offset to this directory. Once we are in the right location, we can cast our structure, which will therefore contain all the data about the file we are parsing.
In the struct, there is a field called, NumberOfNames, which will obviously tell us the number of functions imported by name, so now all we have to do is print the function name and its address and repeat the NumberOfNames procedure times.
The AddressOfFunctions and AddressOfNames will point to tables where each name/function address will be contiguos.
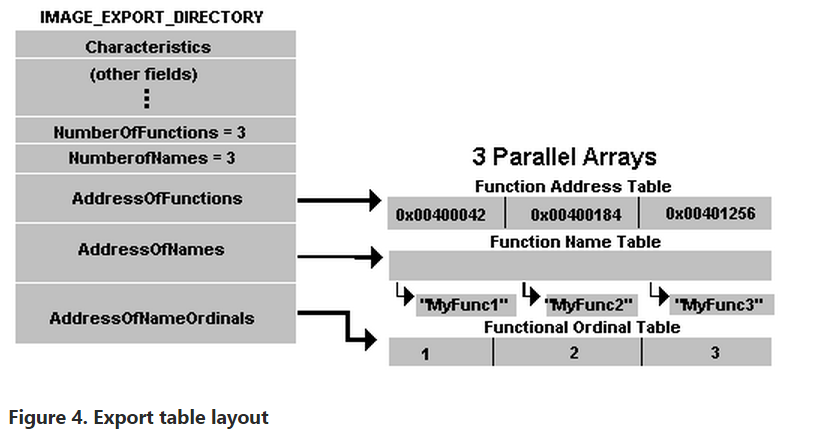
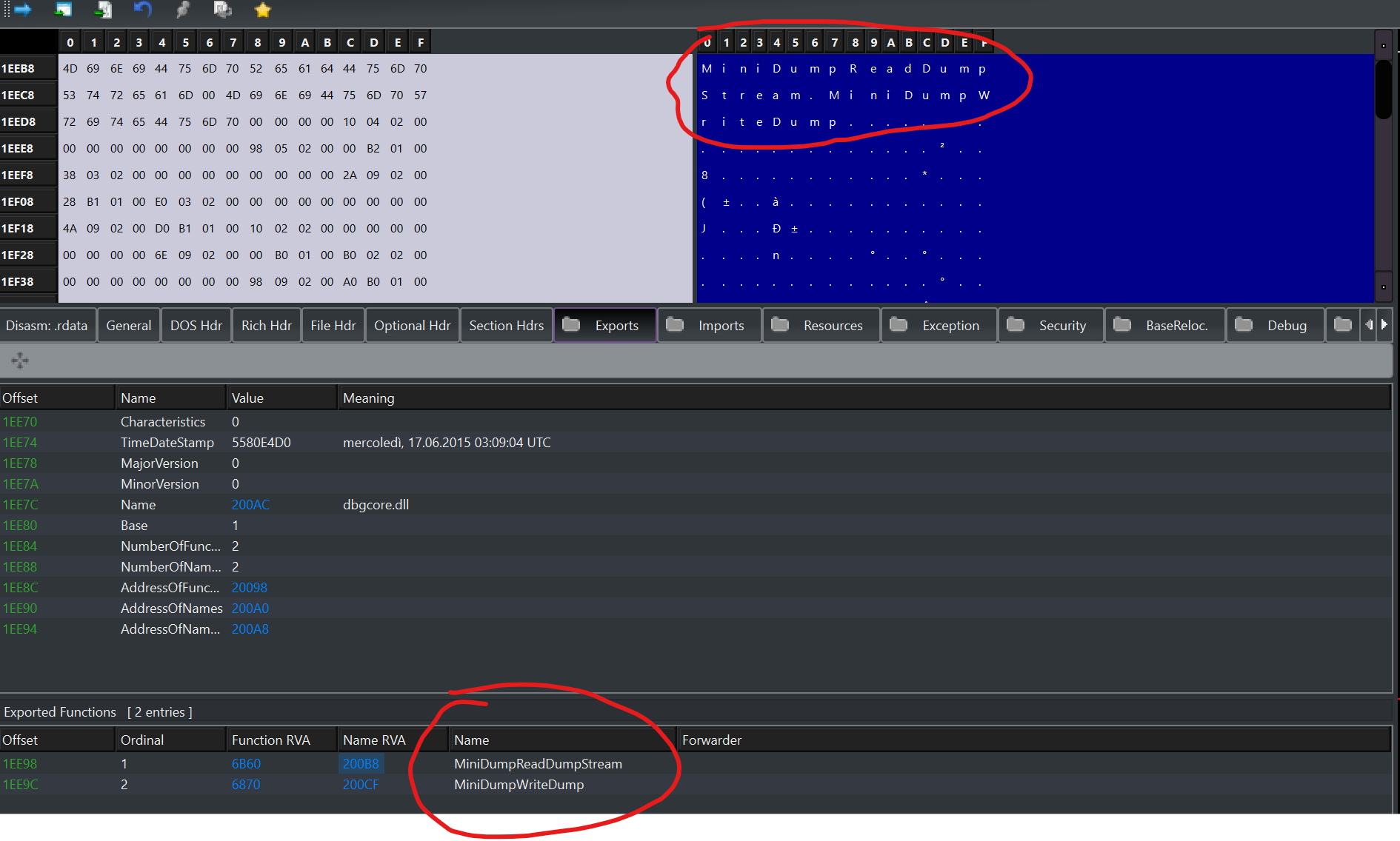
So all we have to do is multiply (as explained earlier), the size of the type we are going to read by the position, and add it to the initial address of the table. (As if we wanted to access an element of an array of that type, via pointer arithmetic.)
To access the function address, all we have to do is read a u32 at the address we want, and for the string, as we did with the imports, read until we find the null character.
Rust
fn dump_export(&mut self) {
let export_rva = match self.pe_type {
PEType::PE32 => {
self.image_nt_headers_32.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_EXPORT.0 as usize]
.VirtualAddress
}
PEType::PE64 => {
self.image_nt_headers_64.OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_EXPORT.0 as usize]
.VirtualAddress
}
};
if export_rva == 0 {
println!("No exports found");
return;
}
let export_offset = self.export_section.PointerToRawData
+ (export_rva - self.export_section.VirtualAddress);
self.seek_export(export_offset);
let mut image_export = IMAGE_EXPORT_DIRECTORY::default();
fill_struct_from_file(&mut image_export, &mut self.file);
for i in 0..image_export.NumberOfNames {
self.dump_export_name(image_export, i);
self.dump_export_f_address(image_export, i);
}
}
fn dump_export_f_address(&mut self, image_export: IMAGE_EXPORT_DIRECTORY, nth: u32) {
let address_of_f_raw = self.export_section.PointerToRawData
+ (image_export.AddressOfFunctions - self.export_section.VirtualAddress)
+ (nth * mem::size_of::<u32>() as u32);
self.seek_addr_export_f(address_of_f_raw);
let mut address_of_f: u32 = 0;
fill_struct_from_file(&mut address_of_f, &mut self.file);
println!("address -> {:x}", address_of_f);
}
fn dump_export_name(&mut self, image_export: IMAGE_EXPORT_DIRECTORY, nth: u32) {
let export_name_raw = self.export_section.PointerToRawData
+ (image_export.AddressOfNames - self.export_section.VirtualAddress)
+ (nth * mem::size_of::<u32>() as u32);
self.seek_export_name(export_name_raw);
let mut name_address: u32 = 0;
fill_struct_from_file(&mut name_address, &mut self.file);
let name_raw = self.export_section.PointerToRawData
+ (name_address - self.export_section.VirtualAddress);
let name = self.get_f_name(name_raw);
println!("{}", name);
}
fn seek_addr_export_f(&mut self, address_of_f_raw: u32) {
self.file
.seek(SeekFrom::Start(address_of_f_raw as u64))
.unwrap();
}
fn seek_export_name(&mut self, export_name_raw: u32) {
self.file
.seek(SeekFrom::Start(export_name_raw as u64))
.expect("Unable to seek export name raw");
}
fn seek_export(&mut self, export_offset: u32) {
self.file
.seek(SeekFrom::Start(export_offset as u64))
.expect("Unable to seek export table");
}
Wrapping up
If you have come this far congratulations, we are officially done!
Here is the output of our PE parser.
Console
Dos Header:
magic -> 0x5a4d
address of the pe file header -> 0xf0
Pe 64
Image Nt Headers 64:
Pe Signature -> 0x4550
File Header:
Machine -> 0x8664
section count -> 0x6
time date stamp -> 0x558104cf
pointer to simble table -> 0x0
num of simbles -> 0x0
size of optional headers -> 0xf0
characteristics -> 0x2022
Optional Header:
Magic -> 0x20b
Major Linker Version -> 0xc
Minor Linker Version -> 0xa
Size Of Code -> 0x19a00
Size Of Initialized Data -> 0x7c00
Size Of Uninitialized Data -> 0x0
Address Of Entry Point -> 0x19a80
Base Of Code -> 0x1000
Image Base -> 0x180000000
Section Alignment -> 0x1000
File Alignment -> 0x200
Major Operating System Version -> 0xa
Minor Operating System Version -> 0x0
Major Image Version -> 0xa
Minor Image Version -> 0x0
Major Subsystem Version -> 0x6
Minor Subsystem Version -> 0x1
Win32 Version Value -> 0x0
Size Of Image -> 0x25000
Size Of Headers -> 0x400
CheckSum -> 0x2a506
Subsystem -> 0x3
Dll Characteristics -> 0x4160
Number Of RVA And Sizes -> 0x10
Data directory:
import directory:
Virtual address -> 0x200e4
Size -> 0x12c
export directory:
Virtual address -> 0x20070
Size -> 0x71
resource directory:
Virtual address -> 0x23000
Size -> 0x408
iat:
Virtual address -> 0x1b000
Size -> 0x2a8
Sections header:
.text
virtual address -> 0x1000
virtual size -> 0x19980
pointer to raw data -> 0x400
size of raw data -> 0x19a00
characteristics -> 0x60000020
.rdata
virtual address -> 0x1b000
virtual size -> 0x5b1a
pointer to raw data -> 0x19e00
size of raw data -> 0x5c00
characteristics -> 0x40000040
.data
virtual address -> 0x21000
virtual size -> 0x620
pointer to raw data -> 0x1fa00
size of raw data -> 0x200
characteristics -> 0xc0000040
.pdata
virtual address -> 0x22000
virtual size -> 0xd44
pointer to raw data -> 0x1fc00
size of raw data -> 0xe00
characteristics -> 0x40000040
.rsrc
virtual address -> 0x23000
virtual size -> 0x408
pointer to raw data -> 0x20a00
size of raw data -> 0x600
characteristics -> 0x40000040
.reloc
virtual address -> 0x24000
virtual size -> 0x3c0
pointer to raw data -> 0x21000
size of raw data -> 0x400
characteristics -> 0x42000040
Import:
import -> msvcrt.dll
name -> __C_specific_handler
iat function address -> 0x20580
function address -> 0x20580
name -> _initterm
iat function address -> 0x20574
function address -> 0x20574
name -> _amsg_exit
iat function address -> 0x20566
function address -> 0x20566
name -> _XcptFilter
iat function address -> 0x20558
function address -> 0x20558
name -> time
iat function address -> 0x20550
function address -> 0x20550
name -> _wsplitpath_s
iat function address -> 0x20540
function address -> 0x20540
name -> _wcsicmp
iat function address -> 0x20534
function address -> 0x20534
name -> wcsstr
iat function address -> 0x2052a
function address -> 0x2052a
name -> towlower
iat function address -> 0x2051e
function address -> 0x2051e
name -> strstr
iat function address -> 0x20514
function address -> 0x20514
name -> _strlwr
iat function address -> 0x2050a
function address -> 0x2050a
name -> wcsncpy_s
iat function address -> 0x204fe
function address -> 0x204fe
name -> ??3@YAXPEAX@Z
iat function address -> 0x204ee
function address -> 0x204ee
name -> free
iat function address -> 0x204e6
function address -> 0x204e6
name -> malloc
iat function address -> 0x204dc
function address -> 0x204dc
name -> memmove
iat function address -> 0x204d2
function address -> 0x204d2
name -> _purecall
iat function address -> 0x204c6
function address -> 0x204c6
name -> swprintf_s
iat function address -> 0x204b8
function address -> 0x204b8
name -> memcpy
iat function address -> 0x20b06
function address -> 0x20b06
name -> memset
iat function address -> 0x20b10
function address -> 0x20b10
import -> api-ms-win-core-misc-l1-1-0.dll
name -> Sleep
iat function address -> 0x205a4
function address -> 0x205a4
name -> lstrcmpiW
iat function address -> 0x2060e
function address -> 0x2060e
import -> api-ms-win-core-sysinfo-l1-1-0.dll
name -> GetSystemTimeAsFileTime
iat function address -> 0x206e2
function address -> 0x206e2
name -> GetVersionExW
iat function address -> 0x20720
function address -> 0x20720
name -> GetVersionExA
iat function address -> 0x205ac
function address -> 0x205ac
name -> GetTickCount
iat function address -> 0x2091a
function address -> 0x2091a
name -> GetSystemInfo
iat function address -> 0x206fc
function address -> 0x206fc
import -> api-ms-win-core-errorhandling-l1-1-0.dll
name -> GetLastError
iat function address -> 0x205bc
function address -> 0x205bc
name -> SetUnhandledExceptionFilter
iat function address -> 0x208b8
function address -> 0x208b8
name -> SetLastError
iat function address -> 0x205ec
function address -> 0x205ec
name -> UnhandledExceptionFilter
iat function address -> 0x2089c
function address -> 0x2089c
import -> api-ms-win-core-libraryloader-l1-1-0.dll
name -> FreeLibrary
iat function address -> 0x205de
function address -> 0x205de
name -> GetProcAddress
iat function address -> 0x205cc
function address -> 0x205cc
name -> LoadLibraryExA
iat function address -> 0x2061a
function address -> 0x2061a
name -> LoadLibraryExW
iat function address -> 0x205fc
function address -> 0x205fc
import -> api-ms-win-core-localregistry-l1-1-0.dll
name -> RegQueryValueExA
iat function address -> 0x2070c
function address -> 0x2070c
name -> RegQueryValueExW
iat function address -> 0x2063c
function address -> 0x2063c
name -> RegOpenKeyExA
iat function address -> 0x2062c
function address -> 0x2062c
name -> RegCloseKey
iat function address -> 0x20650
function address -> 0x20650
import -> api-ms-win-core-handle-l1-1-0.dll
name -> CloseHandle
iat function address -> 0x2065e
function address -> 0x2065e
name -> DuplicateHandle
iat function address -> 0x206aa
function address -> 0x206aa
import -> api-ms-win-core-memory-l1-1-0.dll
name -> MapViewOfFile
iat function address -> 0x206d2
function address -> 0x206d2
name -> VirtualQueryEx
iat function address -> 0x207f4
function address -> 0x207f4
name -> UnmapViewOfFile
iat function address -> 0x20770
function address -> 0x20770
name -> VirtualFree
iat function address -> 0x20688
function address -> 0x20688
name -> ReadProcessMemory
iat function address -> 0x207e0
function address -> 0x207e0
name -> VirtualAlloc
iat function address -> 0x2066c
function address -> 0x2066c
import -> api-ms-win-core-file-l1-1-0.dll
name -> GetFileSize
iat function address -> 0x20762
function address -> 0x20762
name -> WriteFile
iat function address -> 0x2067c
function address -> 0x2067c
name -> CreateFileA
iat function address -> 0x20754
function address -> 0x20754
name -> SetFilePointer
iat function address -> 0x20806
function address -> 0x20806
name -> CreateFileW
iat function address -> 0x20730
function address -> 0x20730
import -> api-ms-win-core-processthreads-l1-1-0.dll
name -> GetCurrentProcess
iat function address -> 0x20696
function address -> 0x20696
name -> TerminateProcess
iat function address -> 0x208d6
function address -> 0x208d6
name -> ResumeThread
iat function address -> 0x207a8
function address -> 0x207a8
name -> GetCurrentProcessId
iat function address -> 0x20904
function address -> 0x20904
name -> GetPriorityClass
iat function address -> 0x207b8
function address -> 0x207b8
name -> GetThreadPriority
iat function address -> 0x207cc
function address -> 0x207cc
name -> SuspendThread
iat function address -> 0x20798
function address -> 0x20798
name -> GetCurrentThreadId
iat function address -> 0x20782
function address -> 0x20782
import -> api-ms-win-core-string-l1-1-0.dll
name -> MultiByteToWideChar
iat function address -> 0x206bc
function address -> 0x206bc
name -> WideCharToMultiByte
iat function address -> 0x2073e
function address -> 0x2073e
import -> api-ms-win-core-heap-l1-1-0.dll
name -> HeapAlloc
iat function address -> 0x20818
function address -> 0x20818
name -> HeapFree
iat function address -> 0x20840
function address -> 0x20840
name -> HeapDestroy
iat function address -> 0x20824
function address -> 0x20824
name -> HeapCreate
iat function address -> 0x2084c
function address -> 0x2084c
name -> HeapReAlloc
iat function address -> 0x20832
function address -> 0x20832
import -> api-ms-win-core-rtlsupport-l1-1-0.dll
name -> RtlLookupFunctionEntry
iat function address -> 0x2086e
function address -> 0x2086e
name -> RtlCaptureContext
iat function address -> 0x2085a
function address -> 0x2085a
name -> RtlVirtualUnwind
iat function address -> 0x20888
function address -> 0x20888
import -> api-ms-win-core-profile-l1-1-0.dll
name -> QueryPerformanceCounter
iat function address -> 0x208ea
function address -> 0x208ea
Export:
name -> MiniDumpReadDumpStream
address -> 6b60
name -> MiniDumpWriteDump
address -> 6870