Web Scraping using Rust 🦀
Foreword: The topics covered in this post will then be further explored with other projects that will be uploaded to my youtube channel. The source code can be found here and in future episodes we will cover more difficult topics such as bypassing cloudflare (with rust undetected chromedriver :D) or downloading videos from streaming sites, using rust of course!
Stay tuned.
Let's start
Prerequisites
Some knowledge is required to follow this post, particularly a basic knowledge of html and css selectors and xpath (more on that later), as well as a knowledge of the dev tools provided by the browser you are using.
Which library we will use and why
The rust ecosystem for web scraping consists of three main libraries: scraper, soup, and thirtyfour. We will focus on the third one, namely thirtyfour, which ironically is the atomic number of selenium (yes, a recall to the famous tool). This is because unlike the first two it allows us to use a webdriver to automate scraping and thus avoid various problems, such as sites that are client-side rendered (such as airbnb and like every website which need realtime update) and other sites that require coockies to be present.
Using the first two,thus limiting ourselves to making a request to the site url, scraping would not have been possible because the site code is generated after the request dynamically and therefore we would not have been able to access the information we were interested in. Moreover, the library offer us multiple methods to get the data we are interested in,via all common selectors e.g. Id, Class, CSS, Tag, XPath, making scraping very flexible.
Now, No more talk and let's get started!
Start scraping airbnb
Rust
pub async fn scrape_airbnb(place: &str) -> Result<(), Box<dyn Error>> {
let driver = initialize_driver().await?;
let url = Url::parse("https://www.airbnb.it/")?;
driver.goto(url).await?;
thread::sleep(Duration::from_secs(2));
search_location(&driver, place).await?;
thread::sleep(Duration::from_secs(2));
scrape_all(driver).await?;
Ok(())
}
This is the function that will be called in the main, to start scraping we need to run our webdriver, which will expose a port that our framework will connect to. In my case I will use chrome and maximize the window. Note: i added a sleep of 2 seconds in order to make the website page load.
Rust
async fn initialize_driver() -> Result<WebDriver, WebDriverError> {
let caps = DesiredCapabilities::chrome();
let driver = WebDriver::new("http://localhost:9515", caps).await?;
driver.maximize_window().await?;
Ok(driver)
}
Next our driver will open our url, in this case that of airbnb.
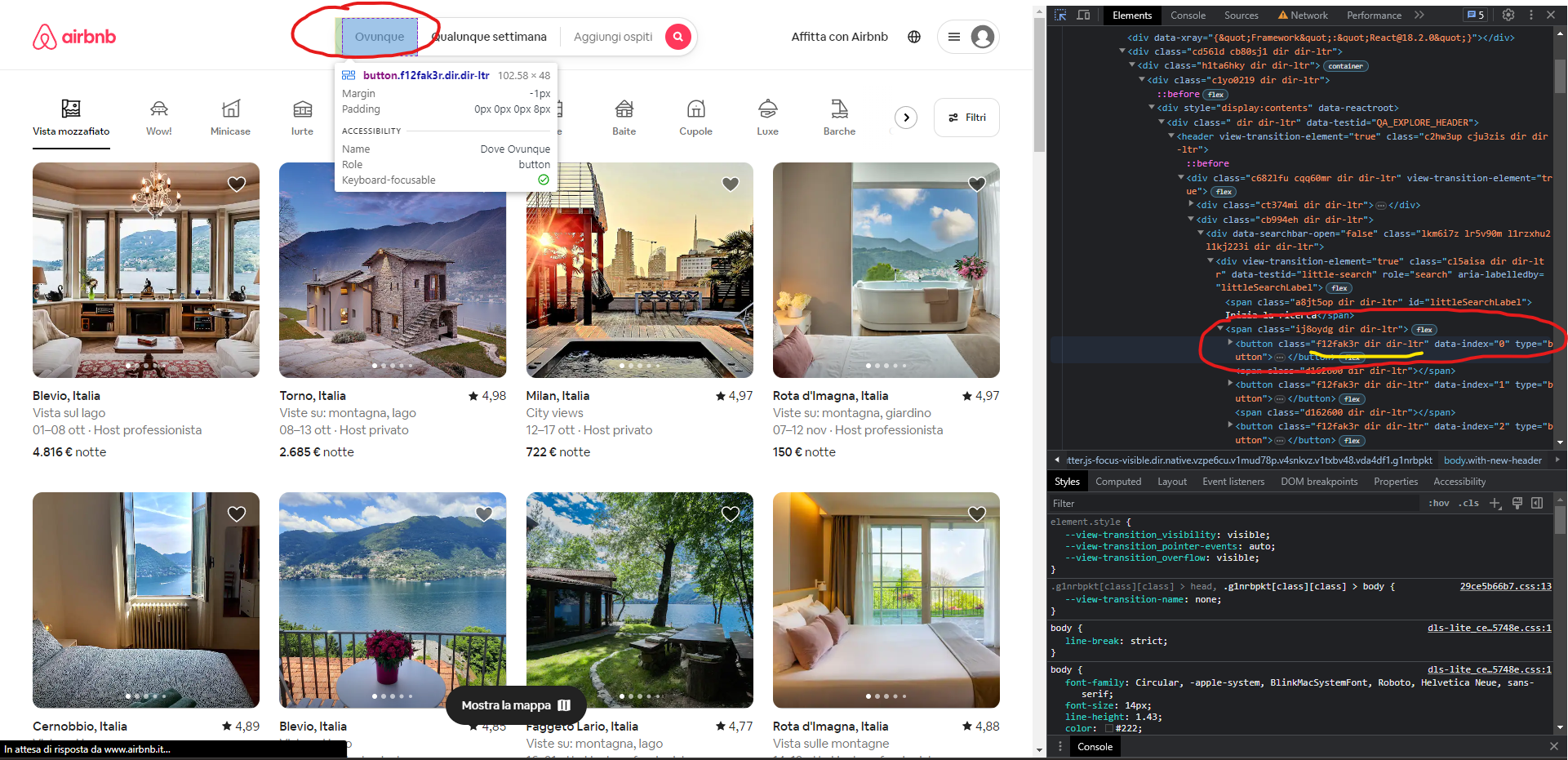
The page we are currently on is this. On the left, circled in red we find the button while on the right the corresponding html element. Underlined in yellow is the class that corresponds to the element, in this case useless but very useful to distinguish between elements of the same type using css selectors. What we want to do now is to press the button that says everywhere (in Italian, ovunque) and then search for our desired place and begin the research.
Rust
async fn search_location(driver: &WebDriver, place: &str) -> Result<(), WebDriverError> {
click_choose_place(driver).await?;
write_place(driver, place).await?;
click_search_button(driver).await?;
Ok(())
}
After copying the css selector associated with the button, we can use the find function provided by the webdriver to search for the element and if it is found, it will be clicked via the click function, associated with the found element instance.
Rust
async fn click_choose_place(driver: &WebDriver) -> Result<(), WebDriverError> {
driver
.find(By::Css("body > div:nth-child(8) > div > div > div:nth-child(1) > div > div.cd56ld.cb80sj1.dir.dir-ltr > div.h1ta6hky.dir.dir-ltr > div > div > div > header > div > div.cb994eh.dir.dir-ltr > div.lkm6i7z.lr5v90m.l1rzxhu2.l1kj223i.dir.dir-ltr > div > span.ij8oydg.dir.dir-ltr > button:nth-child(1)"))
.await?.click().await?;
Ok(())
}

Now all we have to do is enter the location; this is the function that takes care of that.
Rust
async fn write_place(driver: &WebDriver, place: &str) -> Result<(), WebDriverError> {
let input = driver
.find(By::Css("#bigsearch-query-location-input"))
.await?;
input.wait_until().clickable().await?;
input.send_keys(place).await?;
Ok(())
}
In this case after finding the input element we will check that one condition is verified, namely that the element is clickable, in fact after pressing the first button the input box may not have been loaded yet causing an error in the search for the selector and thus compromising the whole scrape. In addition to having the function of clicking on elements found by the driver, we have another high-level one, which allows us to write text (keys) in our element.
Regarding the click of the search button, the situation is analogous to the first case.
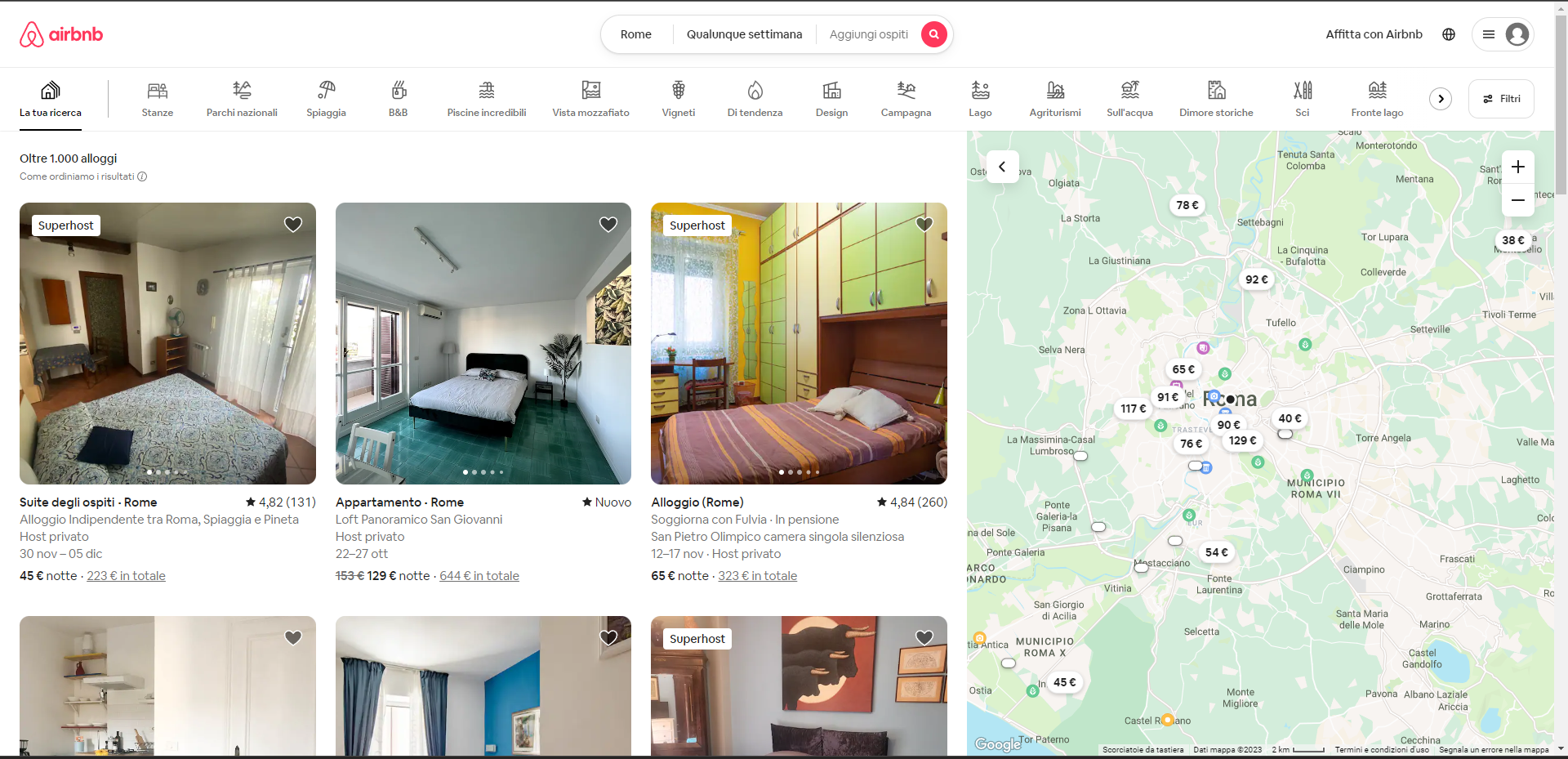
Now we could already start extracting data, but as we scroll further down the page we can see that there are more than one page with results.
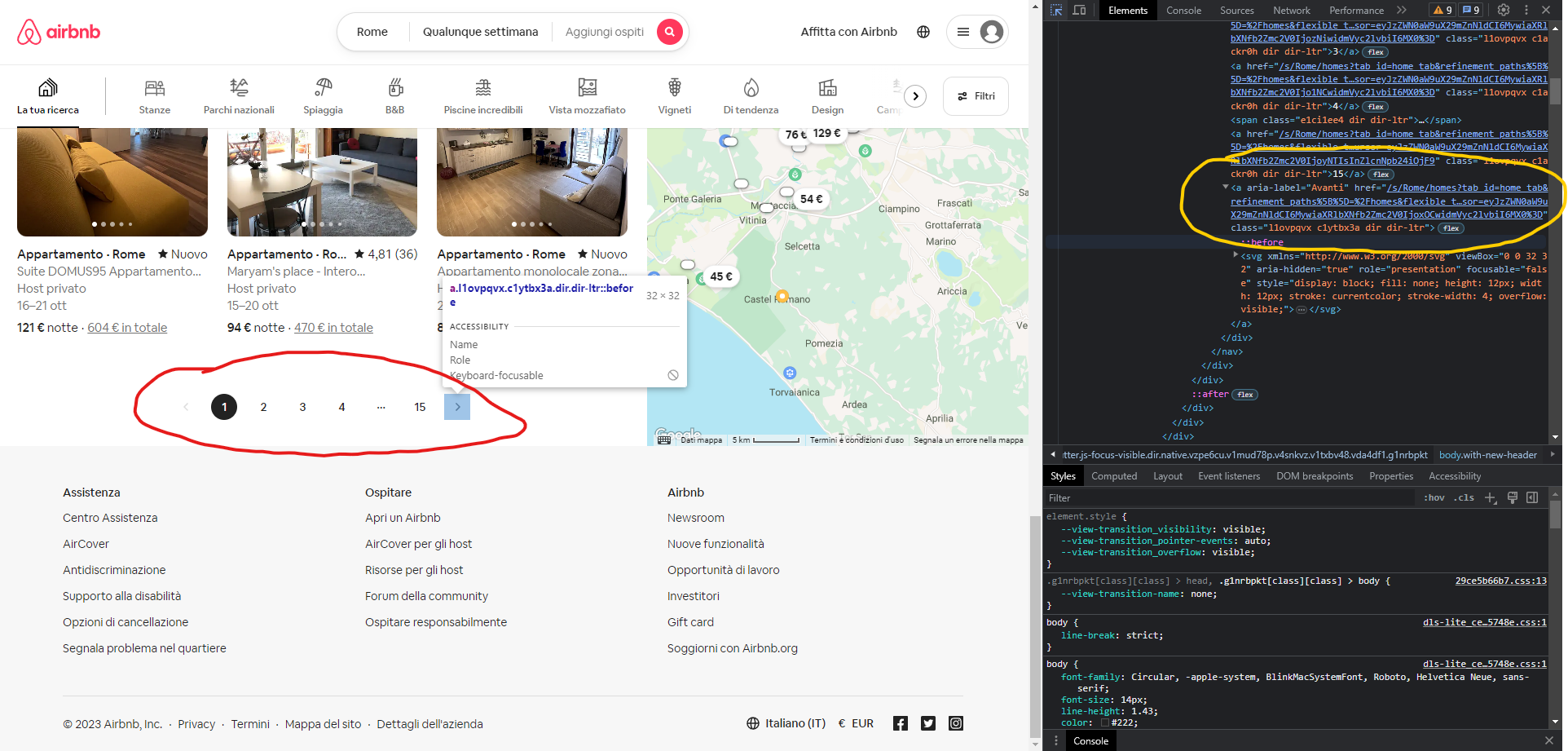
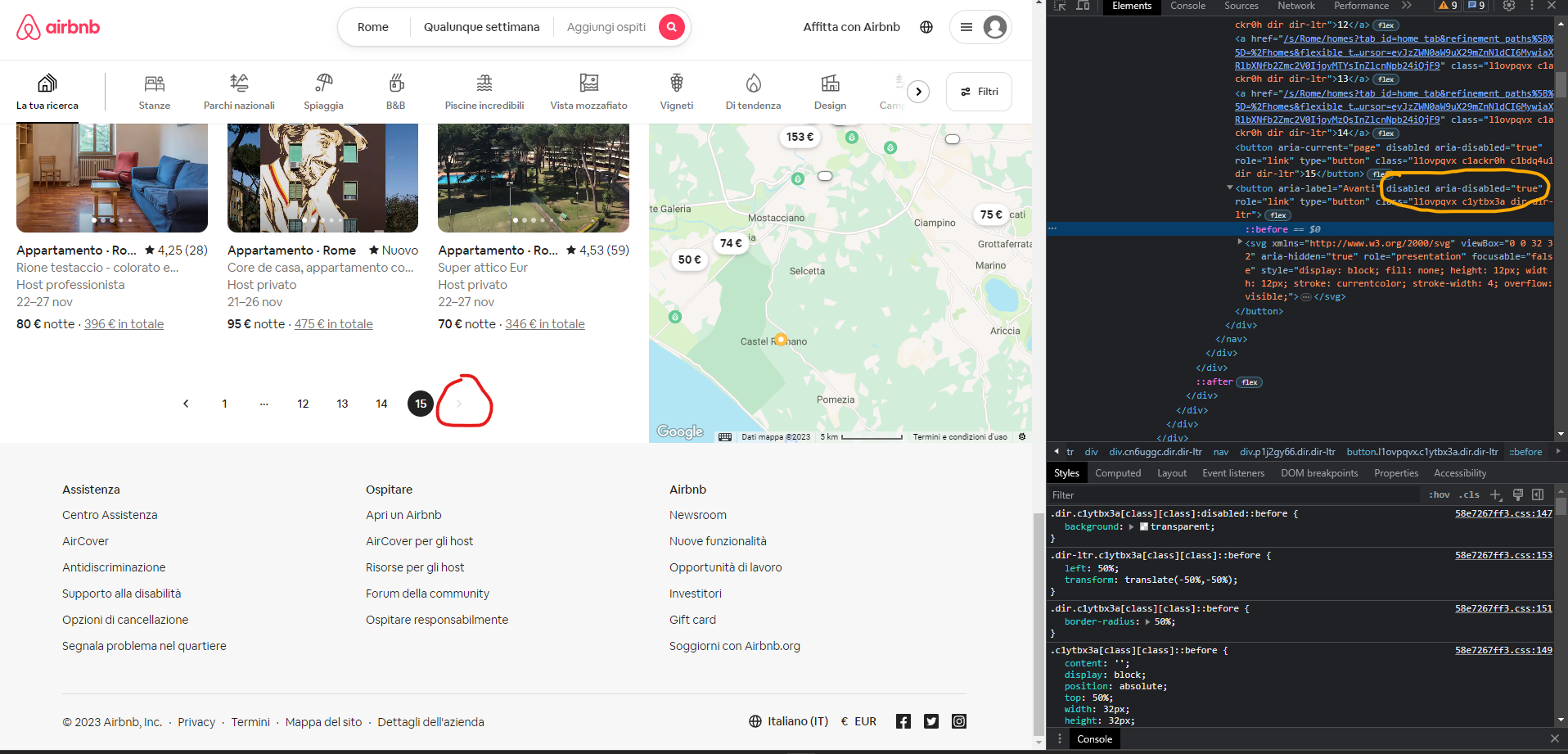
To automate this process, we can keep clicking the button that leads to our page until it is no longer there or, in the case of airbnb, no longer clickable.
Rust
async fn scrape_all(driver: WebDriver) -> Result<(), Box<dyn Error>> {
driver
.execute("window.scrollTo(0, document.body.scrollHeight);", vec![])
.await?;
thread::sleep(Duration::from_secs(1));
let mut wtr = csv::Writer::from_path("airbnb.csv")?;
loop {
if let Ok(next_page_button) = driver.find(By::Css("#site-content > div > div.p1szzjq8.dir.dir-ltr > div > div > div > nav > div > a.l1ovpqvx.c1ytbx3a.dir.dir-ltr")).await {
match next_page_button.is_clickable().await? {
true => {
//start extracting data
let house_elems = get_house_elements(&driver).await?;
for house_elem in house_elems {
let bnb_details = BnbDetails::from(house_elem).await?;
wtr.serialize(bnb_details)?;
}
load_next_page(next_page_button, &driver).await?;
}
false => {
break
},
}
} else {
let house_elems = get_house_elements(&driver).await?;
for house_elem in house_elems {
let bnb_details = BnbDetails::from(house_elem).await?;
wtr.serialize(bnb_details)?;
}
break;
}
}
Ok(())
}
async fn load_next_page(
next_page_button: WebElement,
driver: &WebDriver,
) -> Result<(), Box<dyn Error>> {
next_page_button.click().await?;
thread::sleep(Duration::from_secs(2));
driver
.execute("window.scrollTo(0, document.body.scrollHeight);", vec![])
.await?;
thread::sleep(Duration::from_secs(1));
Ok(())
}
Now focus on the algorithm and not on the functions to extract the information and write it into the csv file.
What we do is scroll to the bottom of the page, so we can get the web page to load completely and be able to work with the elements we are interested in. To do this the driver gives us the ability to run js scripts that enable us to do this action.
Next we check that the button to go to the next page is present, if it is present we click it, once the new page loads we extract the data and then repeat the process, until the button is no longer present.
What we are missing now is to extract the information that we are interested in, in our case a page will contain more than one accommodation, so we will not search for just one item, but for all the items on our page. Attached is the code.
Rust
async fn get_house_elements(driver: &WebDriver) -> Result<Vec<WebElement>, WebDriverError> {
driver.find_all(By::Css("#site-content > div > div:nth-child(2) > div > div > div > div > div.gsgwcjk.g8ge8f1.g14v8520.dir.dir-ltr > div.dir.dir-ltr > div > div.c1l1h97y.dir.dir-ltr > div > div > div > div.cy5jw6o.dir.dir-ltr > div > div.g1qv1ctd.c1v0rf5q.dir.dir-ltr")).await
}
Now there are only 2 steps left, extracting the information and writing it into a csv file.
Rust
#[derive(Debug, Serialize)]
struct BnbDetails {
title: String,
description: String,
host: String,
availability: String,
price: String,
star: String,
}
impl BnbDetails {
async fn from(house_elem: WebElement) -> Result<Self, WebDriverError> {
let title = BnbDetails::get_title(&house_elem).await?;
let description = BnbDetails::get_description(&house_elem).await?;
let host = BnbDetails::get_host(&house_elem).await?;
let availability = BnbDetails::get_availability(&house_elem).await?;
let price = BnbDetails::get_price(&house_elem).await?;
let star = BnbDetails::get_star(&house_elem).await?;
Ok(Self {
title,
description,
host,
availability,
price,
star,
})
}
async fn get_title(house_elem: &WebElement) -> Result<String, WebDriverError> {
house_elem
.find(By::Css("div:nth-child(1)"))
.await?
.text()
.await
}
}
...
This is the struct that contains our data, I only included in the code the method to extract the title, as the others are very similar. The logic is again, to find the element and in this case use the function text to get the text inside the element. I made the struct derive serialize in order to write the fields in the csv file more easily.
Congratulations!!! Our scraper is actually finished. ✅ Let's see it in action (the video is speeded up).
Conclusion
Writing web scrapers using rust and thirtyfour was quite easy, I found the library very simple, especially coming from selenium, plus rust's strong type system and error handling makes it easier to write correct code and allows you to waste less time debugging code. The iterators and functional paradigm that rust offers also makes searching for data much easier and idiomatic.
it was a lot of fun writing this scraper, in the next episode we will use the undetected chrome driver to bypass cloudflare and much more. Stay tuned and let's bring rust up in the web scraping field as well! 🦀🦀🦀